A discovery platform · An academic decision-making platform · Built to remove decision paralysis
Role: Product Manager (Solo) Framework: Double Diamond × Lean Product Process (Dan Olsen) Domain: EdTech / Academic Tools Stage: 0→1 MVP Concept & Prioritization Stack (Proposed): ReactJS · Node.js/Express · PostgreSQL
Project Overview
Choosing the most suitable and feasible thesis topic is one of the most underestimated challenges in graduate education, particularly for Master’s students in interdisciplinary programs who have the freedom to go almost anywhere, but very little scaffolding to help them choose wisely. The difficulty compounds when students don’t just struggle to pick a topic, but struggle to identify a real-world problem worth solving in the first place.
ThesisMatch is an academic discovery platform built specifically to close this gap. It moves beyond traditional university repositories by enriching past theses with qualitative decision-making data, the why behind the what, and matching students to faculty advisors based on demonstrated methodological and industry-specific expertise. The result is a peer-informed, data-driven path from confusion to a confident thesis proposal.
My Role & Process Framework
I conducted this project as a solo PM, applying the Double Diamond Framework to structure my thinking across problem and solution space, combined with the Lean Product Process (Dan Olsen) to validate hypotheses quickly and avoid building toward an unconfirmed assumption.
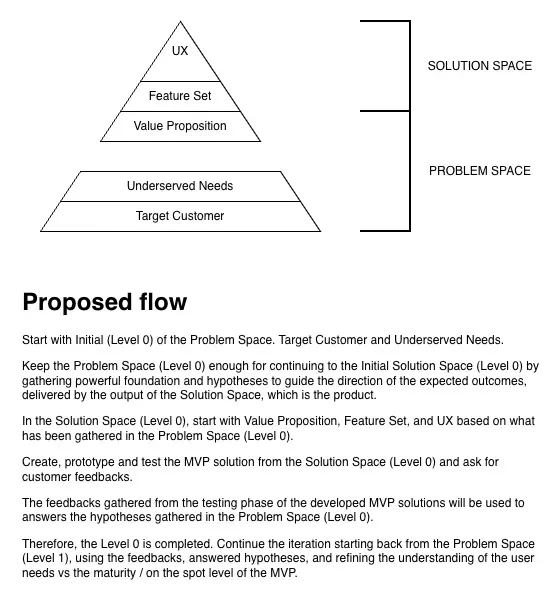
DOUBLE DIAMOND
◆ Discover ──► ◆ Define ◆ Develop ──► ◆ Deliver
(Diverge) (Converge) (Diverge) (Converge)
Problem Space Solution SpaceThe first diamond forced me to stay in the problem space, resisting the urge to jump to features, until I had clearly defined what the product needed to accomplish for the user. Only then did I move into the solution space to figure out how to deliver it.
The Problem I Set Out to Solve
When I mapped the journey of a first-year Master’s student trying to pick a thesis topic and advisor, I found a surprisingly broken experience hidden in plain sight.
Most students land in a digital dead end: institutional repositories like DSpace or EPrints that are essentially glorified filing cabinets. You get a title and an abstract. That’s it. You have no idea why the student picked that topic, what methodology traps they fell into, or whether their background even resembled yours.
Faculty directory pages are equally stale. A list of publications from five years ago and an office room number.
The result? Decision paralysis. Especially brutal in interdisciplinary programs (Design × Business × Technology, for example) where the topic space is vast and the “right answer” is genuinely unclear.
Core insight: Students don’t need more PDFs. They need the qualitative reasoning behind past decisions, and a way to see if their own background maps to a proven path.
Problem Space: Defining the “What”
Using the Lean Product Process, I separated problem space (what the market needs) from solution space (how the product delivers it). The problem space is entirely focused on the benefits the product must provide and the expected outcomes for the user before any feature is imagined.
The central question I asked: What should ThesisMatch allow students to accomplish?
| Expected Outcome | The Underlying Anxiety It Removes |
|---|---|
| Reduce the time needed to define and select a thesis topic | ”I don’t know where to even start.” |
| Avoid decision paralysis when facing a broad, open-ended program | ”There are too many options and none feel right.” |
| Avoid imposter syndrome when comparing themselves to past students | ”I’m not qualified to research this. Others seem so much more prepared.” |
| Know that their progress is visible and in one place, not scattered | ”I have tabs open everywhere. I feel like I’m going in circles.” |
| Enjoy the process of discovering their future research direction | ”This should feel exciting, not overwhelming.” |
This framing became the filter for every subsequent product decision. Any feature that couldn’t be traced back to one of these outcomes was cut or deferred.
Who I Designed For
Primary Persona > “Michael”
- 25-year-old, first-year Master’s student, interdisciplinary program in Bangkok
- Has 2–3 years of prior industry experience; wants to use the thesis to pivot his career
- Pain points: broad major with no clear thesis direction, advisors who feel inaccessible, no peer context for what “a good thesis” looks like in his field
- Behavior: lurks in grad student Facebook/Line groups, cold-emails advisors, gets ghosted
Secondary Persona > Program Directors
- Want aggregate visibility into what students are researching
- Could use macro-trend data to inform curriculum and adjunct hiring decisions
Market Landscape
| Player | What They Do | Why They Fall Short |
|---|---|---|
| eThesis | Admin lifecycle management | Top-down: professors post topics. Zero peer qualitative data. |
| Excelerate | Industry-sponsored research matching | Solves job placement, not academic discovery |
| DSpace / EPrints | Institutional PDF repositories | No behavioral data. No “why behind the what.” |
| Static Faculty Pages | University bios | Outdated. Don’t reflect current or interdisciplinary expertise. |
The gap: No platform captures the student’s decision-making journey and uses it to help the next student. That’s the proprietary dataset that creates a durable moat.
Solution Space: Lean Canvas
With the problem space defined, I moved into the solution space to figuring out how the product delivers on each expected outcome.
| Block | Detail |
|---|---|
| Problem | Decision paralysis in broad programs · Lack of qualitative thesis data · Outdated advisor directories |
| Solution | Qualitative thesis repository · Strength-to-topic matcher · Dynamic advisor profiles |
| UVP | The only academic discovery platform that maps past students’ decision-making criteria and matches your background to the right advisor |
| Unfair Advantage | Proprietary qualitative dataset not captured by any admin portal |
| Customer Segments | 1st/2nd-year Master’s students (interdisciplinary programs, Bangkok) |
| Channels | Grad student Line/FB groups · Student unions · Campus bounty campaigns |
| Revenue | B2C Freemium (premium matching) |
| Cost Structure | Web hosting · DB management · Community marketing |
| Key Metrics | Time to Advisor Match · Activation Rate · MAU through proposal season |
Prioritization: Impact vs. Effort Matrix
Before writing a single spec, I ran a structured prioritization exercise to avoid feature creep and validate the core hypothesis quickly.
HIGH IMPACT
│
│ [Dynamic Advisor Profiles] [Strength-to-Topic Matcher]
│ Medium Effort High Effort
│
│ [Enriched Thesis Feed]
│ Low Effort
│
└──────────────────────────────────────────────────────► HIGH EFFORTWhat made the cut and why
1. Enriched Thesis Discovery Feed (High Impact / Low Effort → Build first)
Standard CRUD with relational tagging. Moving beyond PDFs to surface methodology, timeline, and qualitative “why I chose this” data. Core to the UVP and achievable without ML.
2. Dynamic Advisor Profiles (High Impact / Medium Effort → Build second)
Backend logic aggregates keyword tags from supervised theses and surfaces them on the advisor profile. Solves the “outdated directory” problem without requiring the advisor to do anything manually.
3. Strength-to-Topic Matcher (High Impact / High Effort → Scoped down for MVP)
Instead of a recommendation engine (which requires training data we don’t yet have), the MVP version is a hard-coded onboarding filter: user selects “UX Design background” → platform queries past theses tagged with “UX Design methodologies.” Same outcome, a fraction of the engineering cost. ML can come in V2 once we have behavioral data.
PM decision rationale: I deliberately de-scoped AI/ML for the MVP. The hypothesis I need to validate is whether qualitative peer data reduces friction, not whether the matching algorithm is clever. Premature ML complexity would slow the feedback loop without improving learning.
User Flow: Onboarding to Advisor Shortlist
[1] Account Creation & Profiling
└── Selects program + past professional background strengths
│
▼
[2] "Strength Matcher" Feed
└── Curated feed of past theses from students with similar background tags
│
▼
[3] Qualitative Deep Dive (Thesis Card)
└── Why this topic? · Biggest hurdle · Methodology used · Time to complete
│
▼
[4] Advisor Discovery
└── Dynamic word cloud of actual recent advising expertise (not generic bio)
│
▼
[5] Action
└── Save thesis to Inspiration Board · Add advisor to Contact ShortlistEach step is designed to reduce one specific anxiety: What should I research? Has anyone like me done this? What will I face? Who can actually guide me?
Success Metrics
North Star
Time to Advisor Match average days from account creation to user marking an advisor as “Secured.” This is the single number that tells us whether the product is working.
Supporting Metrics
| Metric | What It Tells Us |
|---|---|
| Activation Rate | % of new users who complete onboarding AND save ≥1 thesis. Validates the feed is useful enough to act on. |
| Thesis Deep Dives per Session | Are users actually reading qualitative data, or bouncing at the abstract? |
| Advisor Profiles Viewed per Session | Are we successfully bridging discovery → advisor contact? |
| MAU through Proposal Season | 3-month retention window aligned to the academic calendar. The product only has to work when it matters. |
The Cold Start Problem, and How I’d Solve It
The platform’s value is entirely dependent on qualitative data. An empty database is useless. This is the biggest 0→1 risk, and I’d address it before writing a single line of product code.
Bounty Program: Offer coffee shop vouchers (Line Pay, GrabFood credits) via campus Facebook groups and student union channels to incentivize recent graduates to upload their theses and complete a qualitative decision survey. The target is 50–80 seeded theses across 3–4 interdisciplinary programs before any public launch.
Why this works: The audience is findable (closed FB groups), the ask is light (one survey, one upload), and the incentive is culturally appropriate for the Bangkok student market. This also generates the first cohort of “alumni authors” who become organic evangelists.
V2 Roadmap
| Feature | Rationale |
|---|---|
| Alumni Messaging | Moves from discovery to direct peer mentorship. Students can contact thesis authors in-app, the next natural step after reading their work. |
| University Admin Dashboard | Once we prove the B2C use case and build a dense qualitative data asset, this opens up a B2B monetization lever: giving universities macro-trend data on student research. |
| ML-Powered Matcher | Once the behavioral dataset exists (saves, views, matches), replace the hard-coded filter with a proper recommendation model. |
Key Technical Decisions & Rationale
As the PM, I defined the system constraints, not just the features.
- PostgreSQL over NoSQL: The data model is inherently relational (students → theses → advisors → tags). The flexibility of NoSQL isn’t needed and would complicate the tagging aggregation logic for advisor profiles.
- ReactJS frontend: Component reusability across thesis cards, advisor profiles, and the Inspiration Board. Also the dominant choice in Bangkok’s frontend hiring market, reduces future talent risk.
- No ML in MVP: Preserved engineering velocity for core data modeling and UX. The “hard-coded filter” approach lets us test the matching hypothesis without training data we don’t yet have.
- Freemium architecture from day one: The free tier must provide genuine value (discovery + shortlisting) to build the data asset. Paywalling too early kills the cold start strategy.
What I Learned
1. Scoping is a product skill, not a concession. The hardest conversation in this project was deciding to ship a filter instead of a recommendation engine. Calling it “scoped down” in a spec is easy; actually holding that line when it feels like you’re “doing less” takes deliberate conviction.
2. The data asset IS the product. Every feature decision eventually came back to: does this help us collect better qualitative data, or consume it? The platform’s defensibility isn’t the UX, it’s the dataset no competitor has thought to build.
3. North Star metrics should survive the academic calendar. Standard monthly retention metrics would have been misleading here. Students have a 3-month proposal window. A product that loses users in month 4 isn’t failing, it succeeded. The metric has to match the user’s actual job-to-be-done timeline.
Portfolio case study: product strategy, prioritization, and user research. Frameworks applied: Double Diamond, Lean Product Process (Dan Olsen). Technical architecture proposed in collaboration with engineering scoping exercise.